本讲座中,何晖光教授首先介绍课题组在医学影像分析方面的几个工作,进而介绍视觉信息编解码的工作。
视觉信息编解码是通过计算方法建立从视觉系统与外界视觉刺激信息之间的映射模型,探索大脑视觉信息处理的过程和机理,其研究不仅有助于探索视觉的加工机制,而且可促进计算机视觉的类脑研究。
2020年6月19日中国科学院自动化研究所何晖光研究员受南方科技大学生物医学工程系刘泉影助理教授邀请在生物医学工程系生物医学讲堂进行了题为《从神经影像计算与分析到视觉信息编解码》的讲座。本文为该讲座的总结推文。
一、研究背景
视觉信息编解码涉及到的问题非常广泛,其中有很多重要问题长期得不到解决。视觉系统是人类感知外部世界的最主要途径,大脑视觉皮层基于视网膜感受器采集到的信息,在我们脑中准确地重建出外界环境的样子。一方面视觉加工过程最快约在200ms以内完成,是一个瞬间、动态的过程。另一方面,外部视觉刺激是多种多样、杂乱无章的,人类的视觉系统却能稳定地识别和理解这些视觉输入。这些问题都需要我们更深入的了解大脑中视觉信息的编解码问题来解决。
从视觉皮层的编码特征上来看,视觉信号从V1-V2-V4-PIT-IT 信息的逐层处理过程中,对应的神经元的感受野越来越大;每层之间感受野增大的系数大体为2.5;高级别的神经元将信息集成在具有较小感受野的多个低级神经元上,编码更复杂的特征。分别来说,V1区是编码的边缘和线条等基本特征;V2区神经元对错觉轮廓有反应,是色调敏感区;V3区是信息过渡区;V4是色彩感知的主要区域,参与曲率计算、运动方向选择和背景分离;IT区是物体表达和识别区(图1、图2)。从近些年来深度学习和机器视觉的发展可以看出,深度卷积网络也与视觉皮层的编码特征呈现出了类似的形态(图3)。
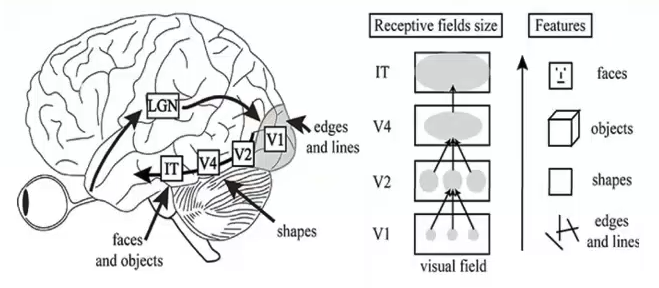
图1 视觉信号分层编码
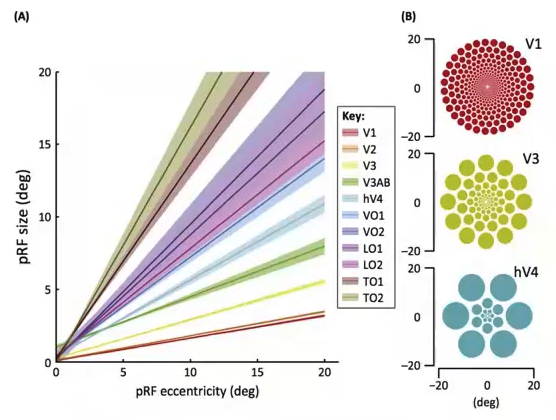
图2 不同区域神经元编码不同特征
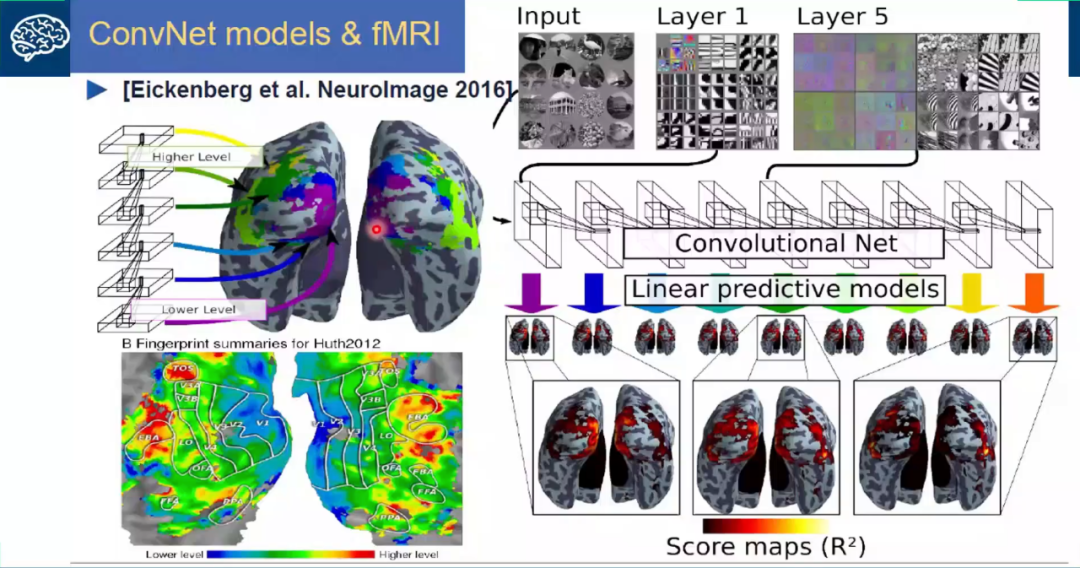
图3 深度卷积网络与大脑分层解码结构
二、视觉信息编解码
视觉编解码是建立视觉刺激和大脑反应之间的关系,编码是将视觉信号转化为大脑反应,解码为将大脑反应转化为视觉信号。何老师认为编码问题在这个过程中有更重要的地位,反映了神经信号加工的机理,更加具有科学价值。在神经信号编解码过程中,往往不会直接使图像对神经信号进行映射,而是先从图像通过非线性变换提取特征,再使用线性编解码器将图像特征和神经信号特征相互连接(图4)。这样做可以降低数据维度,减少计算量和需要的数据量;又能避免编解码过程成为一个黑盒,具有更好的可解释性;同时还能一定程度上避免非线性运算造成的过拟合。
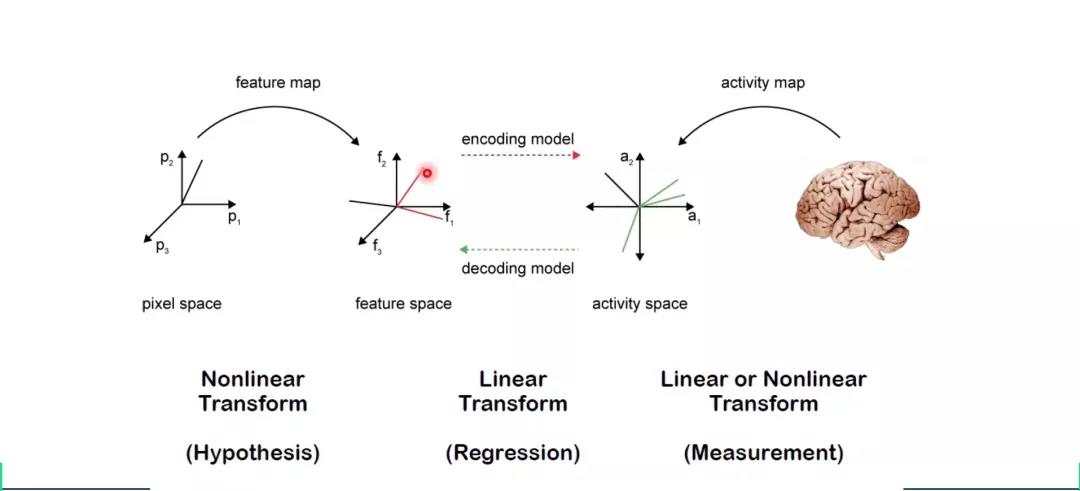
图4 视觉信息编解码过程
在介绍了几个重要的解码模型后,何老师提出了目前视觉信息解码研究中存在的问题。首先,大多数方法只针对分类或辨识任务;其次,重建算法的效果不佳;最后,常用的线性变换手段缺乏生物学基础。其中一部分原因是由于视觉信息解码中的(fMRI)数据特点造成的。这些数据具有维度高、样本量小、噪音严重的特点,对我们应用编解码模型会造成很大的困扰。根据此,何老师提出了《基于视觉信息编解码的深度学习类脑机制研究》项目,该项目有两点目标:1)建立人类视觉系统与外部视觉刺激信息之间的映射模型,利用深度学习对大脑视觉信号进行编解码,探索深度学习的类脑机制;2)通过对视觉信息的编解码,引导深度神经网络建模。
比较直接的办法是将深度神经网络(例如convolutional auto-encoder 卷积自编码器)作为图像和神经信号的特征提取器,再将其特征相互映射(图4)。这种方法被称为两阶段法,即特征提取和映射分开进行。同时也可以使用统一训练的方法,将自编码器图像特征提取和与神经信号相互映射两个步骤合并为一步,进行统一训练(图5)。
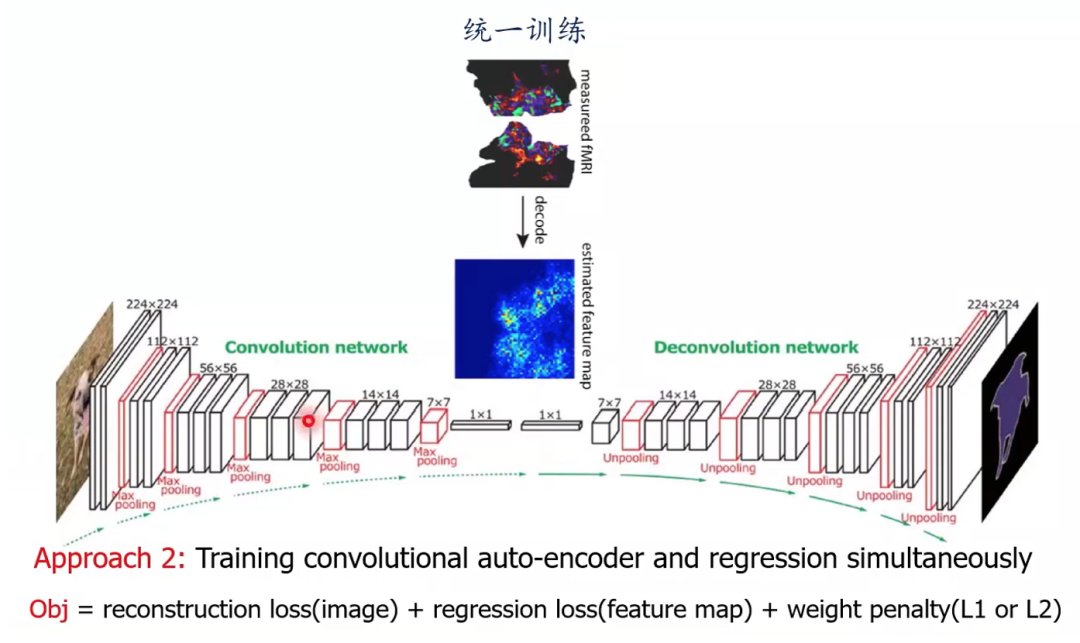
图5 卷积自编码器用于图像与大脑信号特征提取
三、多视图生成式自编码模型
然后何老师介绍了多视图生成式自编码模型(Deep generative multi-view model(DGMM)),该研究由何老师课题组博士生杜长德(已毕业)完成。该模型基于这样一个假设,即视觉图像和大脑响应是同一客体在不同特征空间中的外在表征。由该假设可得视觉图像和大脑响应可以由同一隐含变量通过不同的生成模型得到。这样一来,视觉图形重建问题就转变为了多视图隐含变量模型中缺失视图的贝叶斯推断问题。
所以基于图像我们采用深度神经网络(DNNs)建立推理(Inference)网络和生成(Generative)网络,这样一组推理网络和生成网络构成了变分自编码器(VAE)架构,可以模拟大脑视觉信息处理机制(层次化,Bottom-up, Top-down)(图6,左上到右上)。对于大脑响应,建立稀疏贝叶斯线性模型(图6,左下到右下),模拟体素感受野和视觉信息的稀疏表达准则。这样做可以自动降低体素空间维度,避免过拟合;同时可以利用体素间相关性来抑制噪声,鲁棒性更强;最后由于对体素协方差矩阵施加了低秩约束,降低了计算复杂度。
在训练好这两组推理与生成模型后,给定新的视觉图像输入,就可以通过Bottom-up的推理网络得到隐含表征,再通过线性生成模型预测大脑活动,这就是视觉信息编码通路。反之,给定新的大脑响应,将先验知识(表征相似性分析)融入到贝叶斯推理中,得到隐含表征,再通过Top-down的生成网络预测视觉图像,这就是视觉信息解码通路。
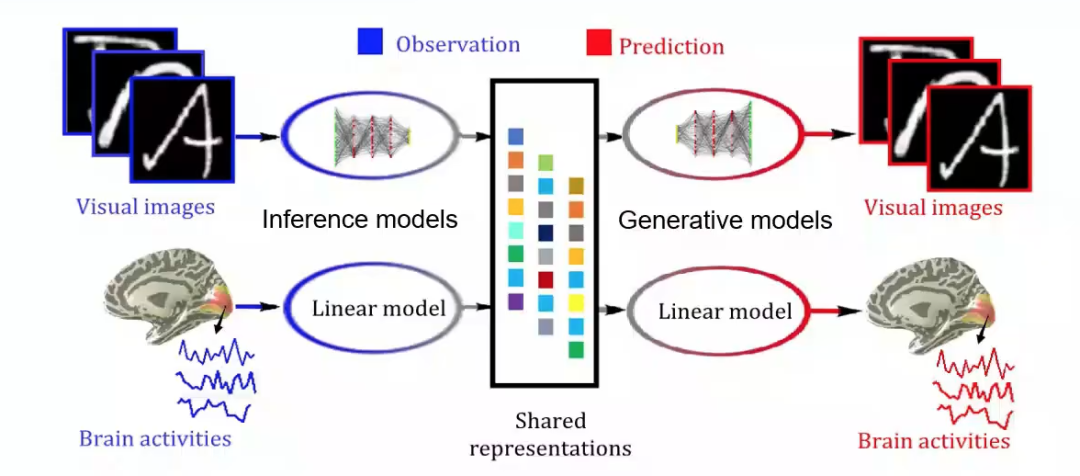
图6 多视图生成式自编码模型结构
在实际训练中,我们将图像和神经信号输入同一个推断模型,来保证生成的隐含表征在同一个空间中,再分别进入各自的生成模型中进行重建(图7)。在测试中,我们通过对输入的大脑响应与一直大脑响应的相似度矩阵,通过贝叶斯推断得到对应的隐含表征,再通过生成网络预测视觉图像(图8)。该研究在三个公开数据集中都进行了测试,这些数据集主要记录了大脑V1和V2的活动。在与多个方法的对比结果中,该模型无论是肉眼观测的图像重建效果还是在数值指标上,均有最好的表现(图9)。在被试差异和模型可解释性上,该研究也进行了分析。最后,通过对fMRI中体素权重的可视化,该模型展现出了在神经科学研究中的潜力。这项研究得到了MIT Technology Review的高度评价,认为该研究在脑机接口方面做出了一项重要的贡献。
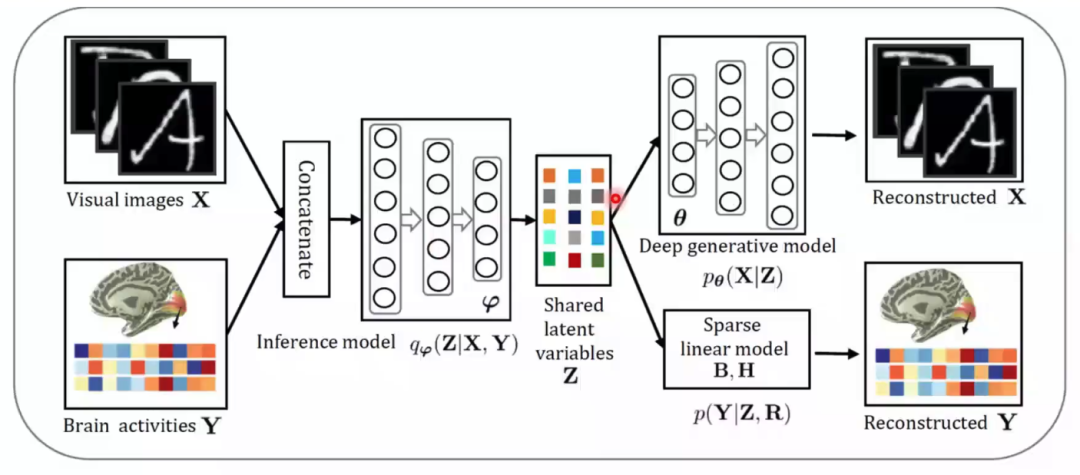
图7 多视图生成式自编码模型训练
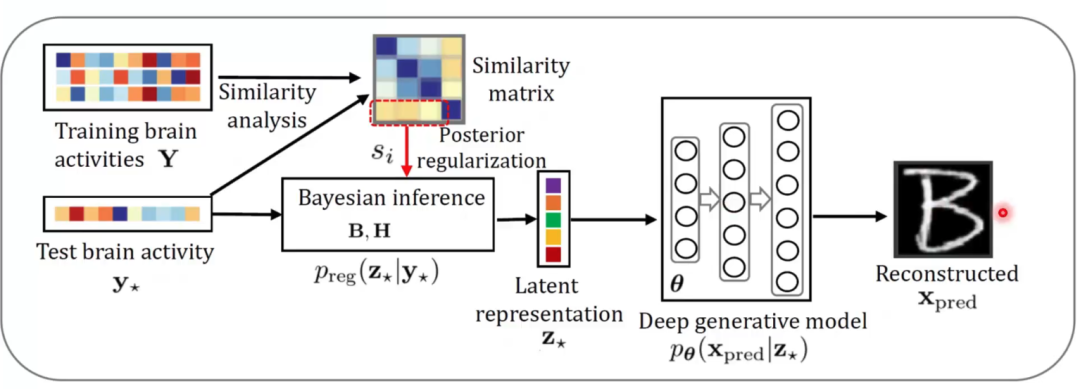
图8 多视图生成式自编码模型测试
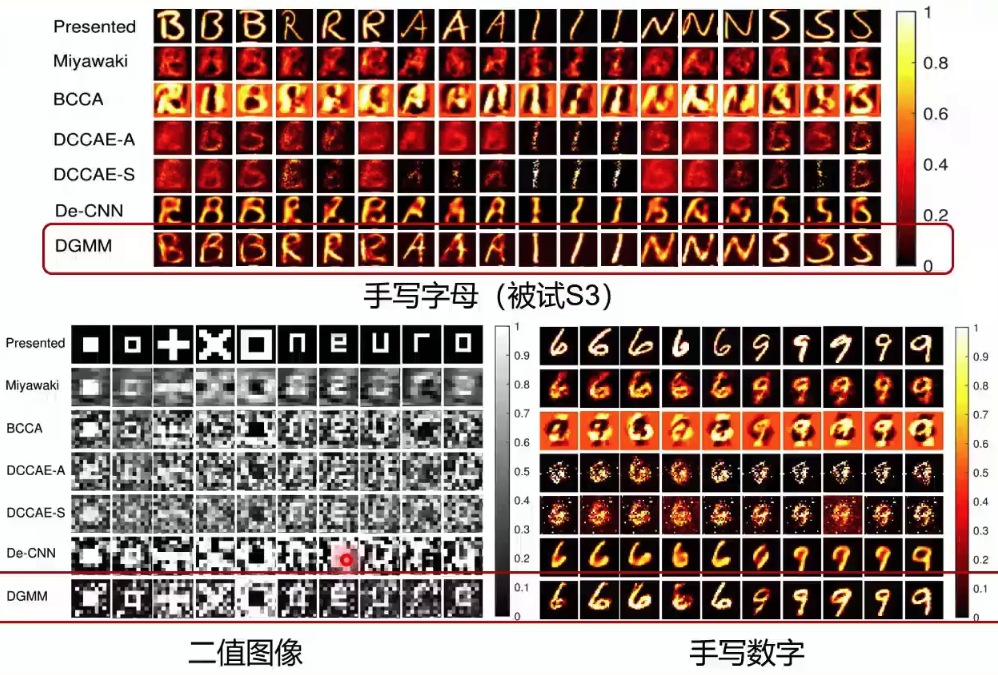
图9 多视图生成式自编码模型生成效果
四、进一步工作
先前研究也存在一些不足之处,例如:
· 多用线性模型:不能学习到深层次的特征
· 单一任务
· 单一模态:只能学到单模态信息
不能利用大量非成对数据
在进一步工作中,将对这些问题进行一一改进:
· 使用深度学习:能学习到层次化的特征,表达能力强
· 多任务:能同时进行分类和重建任务
· 多模态融合:多个模态互相补充有利于解码效果的提升
· 半监督:能对大量的非成对数据,或者对缺失模态补全
随后的研究不仅对图像进行重建,还对其进行了分类;不仅使用了fMRI信号,还使用了EEG信号,不仅使用了成对的监督学习数据,还使用了大量非成对数据进行半监督学习。
五、多模态融合的对抗神经信息编码
在多视图生成式自编码模型基础上,何老师课题组博士生李丹搭建了新的网络,以用于基于多模态融合的对抗神经信息解码。从图10中,我们可以了解该网络的框架。最上层输入图片到标签的过程是一个AlexNet,该网络可以学习图片的分类标签,并在fc7层输出一组语义特征。对于文本或EEG信号这样的非图像信息,作者也训练一个网络来提取语义特征fc2和分类。当这两个网络的数据是成对数据的时候,在两组语义特征间计算一个损失,使两组特征相互联系。对于非图像的网络,作者提取了语义特征和分类标签输入一个生成器生成图像。生成图片之后,将图片输入一个判别网络判断图片是真实图片还是生成图片。如果是成对数据生成的图片,还要将生成图片和原始图片一起输入另一个判别网络,以判断两张图片是否对应。
在测试中,我们就可以输入非图像信息(大脑信号或文本)提取语义特征和分类,再输入训练好的生成器重建图像信息。
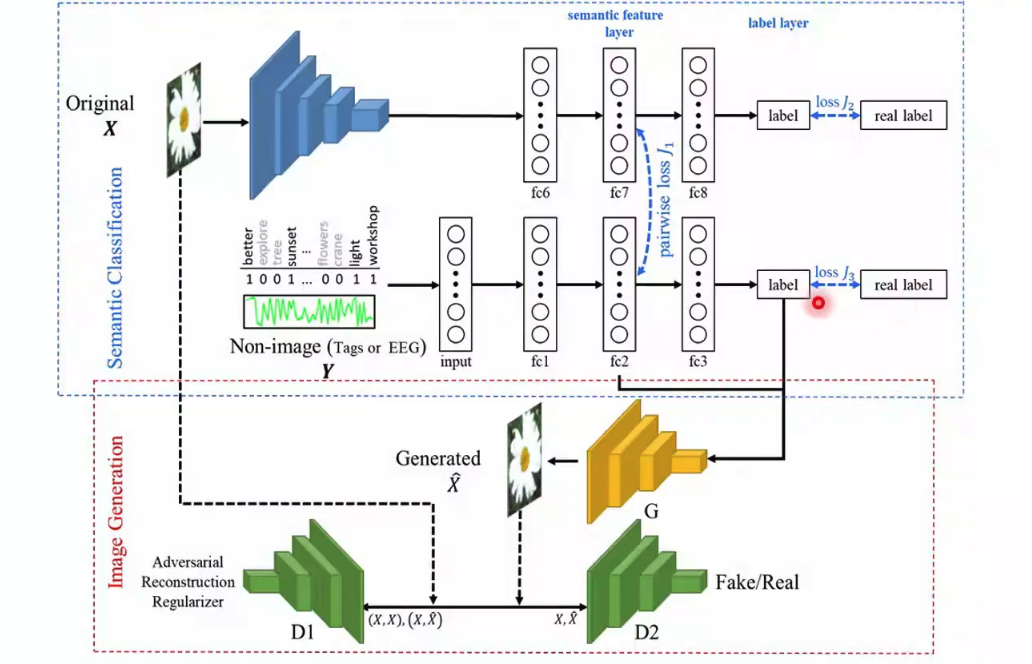
图10 基于多模态融合的对抗神经信息解码网络结构
在以上网络结构的条件下,基于fMRI信号的半监督跨模态图像生成,在实践中取得了较多视图生成式自编码模型更好的效果。基于EEG信号的半监督跨模态图像生成(图11)中也可以看到,由于使用了GAN,生成的图片较之前更为清晰;且由于输入了语义信息,包含了明确的语义特征。总的来说,这个研究将大脑活动的语义学习和图像重建任务统一在同一个框架下,使得解码结果语义明确。同时充分利用非成对的图像数据可以很好的辅助跨模态图像生成任务,使图片重建质量提升,变得更加清晰。

图11 基于EEG信号的半监督跨模态图像生成示例
六、其他思路
接下来何老师分享了其他的一些思路。同样是对之前模型的扩展,将多视图生成式自编码模型中添加了语义这一输出,就可以得到语义信息的解码(图12)。由于图像刺激的类别或者向量包含了图像刺激中的高层次语义信息,该模型可以把大脑响应解码到高层次的语义空间。
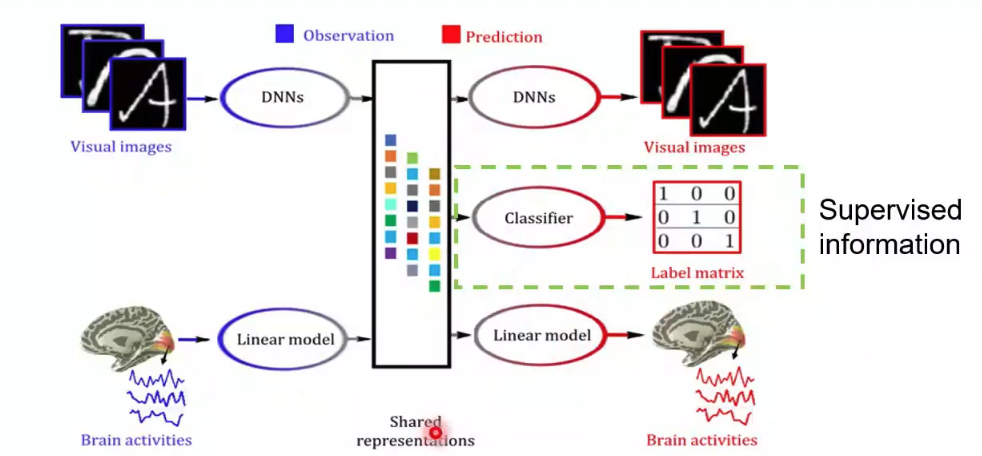
图12 语义信息的解码示例
将不同人的大脑信号看做不同的视图,再利用多视图生成式自编码模型,就可以得到多被试解码与脑-脑通讯模型(图13)。该模型可以综合利用多个被试的大脑响应数据,提高模型的泛化能力。如果我们将一个人的大脑响应解码到另一个人的大脑响应上,则该模型不仅可以实现单个被试的大脑响应解码,还可以实现多个被试间大脑响应的相互转换。
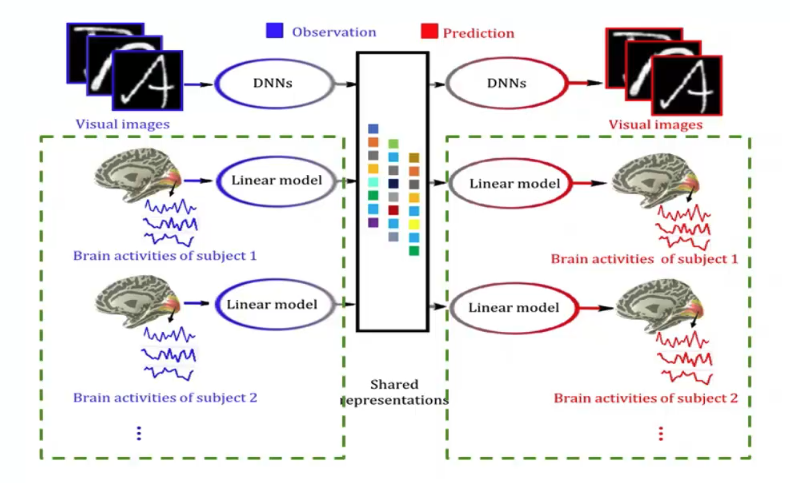
图13 多被试解码与脑-脑通讯模型示例
类似的,多视图生成式自编码模型还可以应用在更加复杂的工作上,例如动态图像(视频)重建。如何根据大脑响应重建动态的视觉刺激场景是一个更具挑战性的问题。将“推理网络”和“生成网络”的类型从多层感知机(MLPs)或卷积神经网络(CNNs)升级为可以处理时间序列数据的递归神经网络(Recurrent Neural Networks, RNNs),便可以尝试进行动态视觉场景的重建。
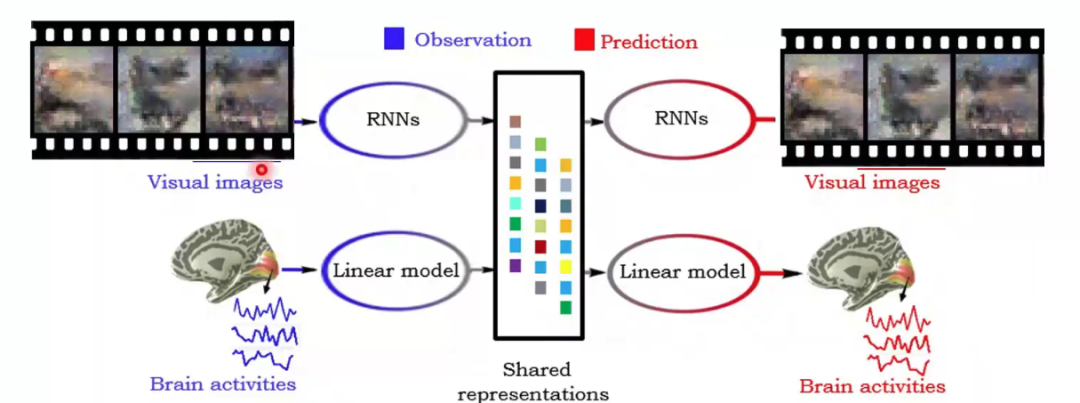
图14 动态图像(视频)重建模型示例
七、总结和展望
何老师对视觉信息编解码的工作做了如下总结和展望:
本质:建立外界视觉刺激信息与大脑响应之间的映射模型
编码:通过研究视觉信息编码,建立类脑计算模型
解码:通过研究视觉信息解码,服务于脑机接口研究
模型:提出了基于多视图生成模型的双向建模框架
结果:在图像重构(信息编码)方面性能优异
展望:
· 复杂自然场景的重构工作还在进行中
· 将采用动态编解码,比如变分RNN,进行视频重建
· 借鉴机器翻译、图像翻译、对偶学习、自监督学习等思想
· 尝试其他类型的深度生成模型,如GAN等
· GAN与VAE的结合
该讲座介绍的研究的原文和代码如下,欢迎感兴趣的同学进一步研究:
代码:https://github.com/ChangdeDu/DGMM
网站:http://nica.net.cn
参考文献:
1. Mauro Manassi, Bilge Sayim, Michael H. Herzog, When crowding of crowding leads to uncrowding, Journal of Vision 2013;13(13):10. doi: https://doi.org/10.1167/13.13.10.
2. Kendrick N. Kay, Jonathan Winawer, Aviv Mezer, and Brian A. Wandell, Compressive spatial summation in human visual cortex, Journal of Neurophysiology 2013 110:2, 481-494
3. Chang de Du, Chang ying Du, Lijie Huang, Huiguang He, Reconstructing perceived images from human brain activities with Bayesian deep multiview learning, IEEE Transactions on Neural Networks and Learning Systems, 2019/8(2018/12/12),30(8), pp:2310-2323,
4. Dan Li, Changde Du, Huiguang He, Semi-supervised cross-modal image generation with generative adversarial networks, Pattern Recognition, 2020/4(2019/11/12),100,pp:107085,
5. Changde Du, Lijie Huang, Changying Du, Huiguang He. Hierarchically Structured Neural Decoding with Matrix-variate Gaussian Prior for Pereceived Image Reconstruction. AAAI 2020
本文作者:NCC lab 魏晨
校对:何晖光
广东省深圳市南山区学苑大道1088号
bme@sustech.edu.cn

关注微信公众号




